Conceitos básicos
Estes são os conceitos da matéria de Machine Learning para que eu conseguisse elaborar os exercícios cobrados na matéria.
Sobre IA
A Inteligência Artificial serve para automatizar a mão de obra humana. Ela pode ser categorizada em:
-
Symbolic IA: se concentra em representar o conhecimento da IA por meio de símbolos e regras. Usamos aqui o conhecimento do primeiro semestre da tabela verdade para saber se uma proposição é verdadeira ou falsa.
-
Connectionist AI: é a IA baseada em redes neurais e se concentra em cálculos e inferências matemáticas.
-
Neuro-Symbolic AI: é a intersecção entre o raciocínio simbólico com as redes neurais, o que potencializa os pontos fortes das outras IA's para que a Neuro-Symbolic AI consiga resolver problemas complexos e ao mesmo tempo aprender com os dados.
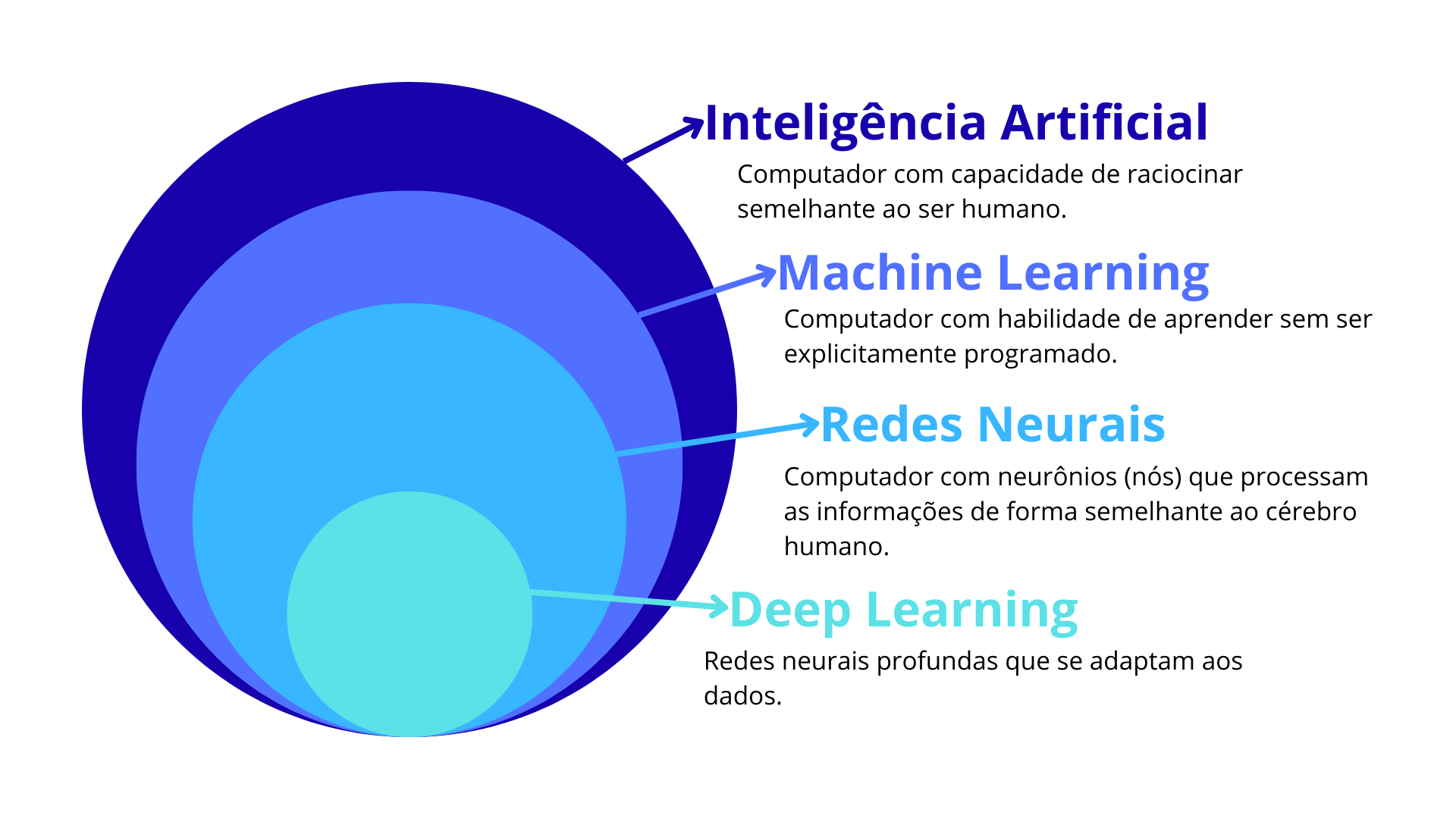
Machine Learning
Mas, o que é o Machine Learning?
Esta técnica serve para que a máquina aprenda a partir dos dados, com o intuito de que o sistema consiga resolver problemas mais complexos e que melhorem seu desemepenho, sem que sejam programados necessariamente o tempo todo de execução.
Dentro do Machine Learning, as técnicas são divididas em duas grandes categorias principais: o aprendizado supervisionado e o aprendizado não supervisionado.
Aprendizado supervisionado
O aprendizado supervisionado é quando treinamos um modelo com uma base de dados rotulados. Isso faz com que o sistema aprenda os padrões e faça previsões com uma base de dados novas e inéditas.
USADO EM: tarefas de classificação e tarefas de regressão. -> abordagem eficaz quando existe uma relação entre as variáveis feature e target.
- Os dados rotulados nada mais são do que o conjunto em que cada linha tem um valor de resposta correto, que você usa para ensinar o modelo. A variável target é considerada como o rótulo, por ser a variável resposta.
Aprendizado não supervisionado
O aprendizado não supervisionado envolve uma base de dados não rotulada, ou seja, o próprio modelo deve encontrar padrões e relacionamentos dentro dos dados que não tem uma orientação explícita.
USADO EM: análises exploratórias de dados e extração de recursos (clusterização e redução de número de recursos em um conjunto de dados) -> abordagem eficaz quando temos que descobrir estruturas ocultas em uma base de dados.
Aprendizado por reforço
Essa técnica é mais comumente utilizada quando o sistema precisa tomar decisões sequenciais com o ambiente e receber um feedback na forma de ganho ou perca.
USADO EM: jogos ou controle robótico.
As técnicas para aprendizado da máquina resolve uma variedade de problemas, e os principais deles são:
-
Problema de classificação: envolve a previsão de categorias discretas (valores inteiros) ou rótulos futuros com base na feature.
-
Problema de regressão: envolve a previsão de valores contínuos.
Modelos
Temos modelos que são com aprendizado supervisionado e com aprendizado não supervisionado. Veja a distribuição dos algoritmos:
Para a construção dos modelos, normalmente seguimos algumas etapas. São elas:
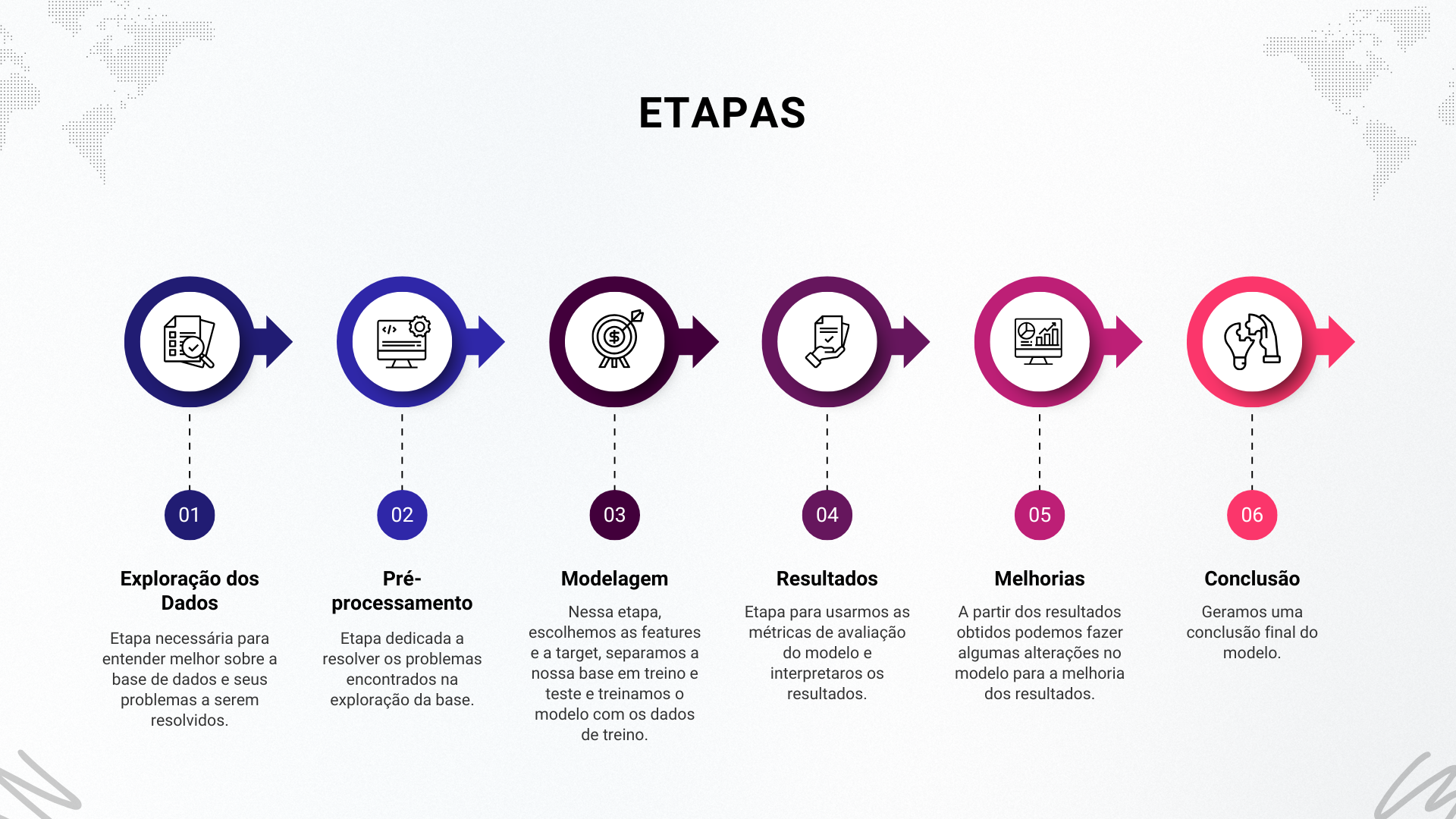
-
Exploração dos Dados (EDA): Nesta etapa, os dados são analisados para entender suas características, identificar padrões e detectar possíveis problemas, como: valores ausentes ou outliers.
-
Pré-processamento: Os dados são limpos e preparados para a modelagem. Isso pode incluir a normalização, transformação de variáveis categóricas em numéricas (usando técnicas como One-Hot Encoding ou Label Encoding), tratamento dos valores ausentes. Comparativo Técnico: Label Encoding vs One Hot Encoding/
-
Modelagem: A árvore de decisão é construída a partir dos dados de treinamento. O algoritmo seleciona as features que melhor dividem os dados em cada nó, com base em critérios como entropia e ganho de informação.
-
Resultados: O modelo é avaliado usando o conjunto de teste para medir sua precisão e capacidade de generalização. Métricas como acurácia, precisão, recall e F1-score são comumente usadas.
-
Melhorias: Nesta etapa, é importante revisarmos os resultados do modelo e ver se tem como fazer melhorias, como tirar algumas variáveis insignificantes e etc.
-
Conclusão: Os resultados são interpretados e as decisões são tomadas com base nas previsões do modelo. A árvore de decisão pode ser visualizada para entender como as decisões foram feitas.
Referências
- Machine Learning Mastery - Decision Trees
- Machine Learning Mastery - KNN
- Machine Learning Mastery - K-Means
- Scikit-Learn - Decision Trees
- Scikit-Learn - KNN
- Scikit-Learn - K-Means
- Wikipedia - Decision Trees
- Wikipedia - KNN
- Wikipedia - K-Means
- Towards Data Science - Decision Trees
- Towards Data Science - KNN
- Towards Data Science - K-Means
- GeeksforGeeks - Decision Trees
- GeeksforGeeks - KNN
- GeeksforGeeks - K-Means